Use memory mapping to speed up the reading of pytorch data set
Author:Data School Thu Time:2022.08.14

Source: Deephub IMBA
This article is about 1800 words, it is recommended to read for 9 minutes
This article will introduce how to use memory mapping files to speed up the loading speed of the PyTorch data set.
When using PyTorch to train neural networks, the most common bottleneck -related bottleneck is the module of data loading. If we transmit data through the network, there is no other simple optimization method except for pre -retreating and cache.
However, if the data is stored locally, we can optimize the reading operation by combining the entire data set into a file and then map it to the memory. In this time, we do not need to access the disk when reading the data. Instead, it is directly from the memory directly from the memory. Reading can speed up the operation.
What is memory mapping file
Memory-Mapped file is loaded to the memory with complete or part of the file, so that the file can be manipulated by load or store instructions related to the memory address. To support this function, the modern operating system will provide a system call called MMAP. This system calls a virtual memory address (VA), length (Len), Protection, some logo positions, a file descriptor that opens the file, and offset.
Due to the additional abstraction layer of virtual memory representatives, we can map files with much larger physical memory capacity than the machine. The memory segment (called page) required for running processes is obtained from external storage and automatically copied from virtual memory manager to the main memory.
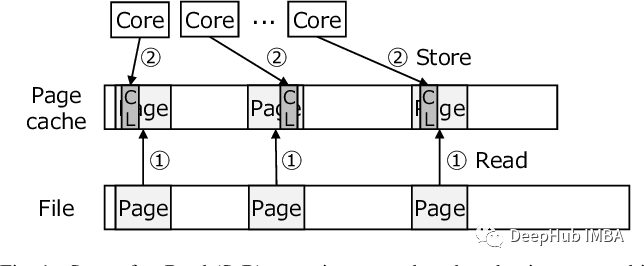
Using memory mapping files can improve I/O performance, because ordinary reading/writing operations performed by system calls is much slower than changes in local memory. For the operating system, the file is loaded in a "inert" manner loading in a "inert" manner loading Usually only one page at a time, so even for large files, the actual RAM utilization rate is the lowest, but the use of memory mapping files can improve this process.
What is pytorch dataset
PyTorch provides two main modules for processing data pipes when training models: dataset and dataLoader.
DataLoader is mainly used as the loading of DataAre, which provides many configurable options, such as batch processing, sampling, pre -reading, transformation, etc., and abstract many methods.
DataSet is the actual part of our dataset processing. Here we read the process of reading data when writing training, including loading samples to memory and necessary conversion.
For dataset, it must be implemented: __ init _, __ len__, and __getITEM__.
Implement customized data set
Next, we will see the implementation of the three methods mentioned above.
The most important part is in __init__, and we will use the NP.Memmap () function in the numpy library to create a NDARRAY to map the memory buffer to the local file.
When the dataset is initialized, the NDARRAY is filled with iterative objects. The code is as follows:
Class Mmapdataset (DataSet): Def __init __ ( Input_iter: Iterable [np.ndaRay], transform_fn: call , Any] = None, > Labels_iter: Iterable [np.ndarray], mmap_path: str = none, size: int = none, ) -& none: super () .__ init __ () Self.mmap_inputs: np.ndarray = None Self.mmap_labels: np.ndarray = None Self.transform_fn = transform_fn if mmap_path is none: mmap_path = os.path.abspath (os.getcwd ()) Self._mkdir (mmap_path) self.mmap_input_path = os.path.join(mmap_path, DEFAULT_INPUT_FILE_NAME) self.mmap_labels_path = os.path.join(mmap_path, DEFAULT_LABELS_FILE_NAME) self .length = size for ID x, (input, label) in enumerate (zip (input_iter, labels_iter)): if self.mmap_inputs is none: Self.mmap_inputs = Self ( code> Self.mmap_labels_path, label.dtype, (Self.Length, *label.shape) Self.mmap_input_path, input.dtype, (Self.length, *Input.shape) ) Self.mmap_labels = Self._init_mmap ( ) Self.mmap_inputs [IDX] [::: [:: [IDX] [:: [:: [IDX] [:: [:: [IDX] [:: [:: [IDX] [:: [:: [IDX] [:: [:: [IDX] [:: [:: [IDX] [:: [: [IDX] [:: [: [IDX] [::: [IDX] [:: [:: [IDX] [:: [:: [IDX] [::: [IDX] [:: [: [IDX] [:: [: [IDX] [:: [: [IDX] [::: [IDX] [:: [:: [IDX] [:: [: [IDX] [:: [::] [IDX] [: ] = Input [:] Self.mmap_labels [IDX] [:] = label [:] def __getitem___ (Self, IDX: int) -&
Tuple [union [np.ndarray, torch.tensor]]: if self.transform_fn: Return Self.transform_fn (self.mmap_inputs [IDX]), Torch.Tensor ( Self.mmap_labels [IDX]) Return Self.mmap_inputs [IDX], Self.mmap_labels [IDX] def> __len __ (self) -& int: Return Self.length We also use two auxiliary functions in the code provided above.
DEF _mkdir (Self, Path: Str) -& None: if om.Path.exists (PATH): Return Try: Os.makedirs (OS.Path.diRName (PATH), Exist_ok = TRUE) Except: Except: Except: RAISE VALUEERRROR ( "FAILED to Create the Path (Check the user write permissions)." Code> DEF _Init_mmap (Self, Path: Str, DTYPE: NP.DTYPE, ShaPE: Tuple [int], Remove_existing: BOOL = FALSE) -& NP.NDARAY: Open_mode = "R+" If Remove_existing: Open_mode = "W+" Return NP .memmap ( Path, DTYPE = DTYPE, mode = open_mode, < Code>)
It can be seen that the main difference between our custom dataset and the general situation above is the NP.Memmap () called in _init_mmap, so here we make a simple explanation of np.Memmap ():
Numpy's MEMMAP object allows large files to be divided into small segments for reading and writing instead of reading the whole array into memory at one time. MEMMAP also has the same method as an ordinary array. Basically, as long as it is an algorithm that can be used for NDARAY, it can be used for MEMMAP.
Using a function NP.Memmap and passing into a file path, data type, shape, and file mode, you can create a new Memmap stored binary files stored on the disk to create memory mapping.
For more introductions, please refer to Numpy's documentation, so I will not explain in detail here.
Benchmarks
In order to improve the performance of the actual display, I compared the realization of the memory map data with the general dataset of a classic way of reading files. The data set here consists of 350 JPG images.
From the following results, we can see that our data set is more than 30 times faster than ordinary data sets:
Summarize

The method introduced in this article is very effective when the data reading of PyTorch is read, especially when using large files, but this method requires a lot of memory. There is no problem when doing offline training, because we can fully control us to fully control usData, but if you want to apply it in production, you need to consider it, because we cannot control some data in production.The last Numpy's document address is as follows:
https://numpy.org/doc/stable/reference/GENETED/numpy.Memmap.html
Those who are interested can understand in detail.
The author of this article also created a project on GitHub. Those who are interested can see:
https://github.com/dacus1995/pytorch-mmap-dataset
Author: Tudor Surdoiu
Edit: Huang Jiyan
- END -
How to "four seasons like spring"?How to "online"?Revealing the aerospace technology of the Tiangan experimental cabin

On July 24, the first experimental cabin in the construction stage of my country's...
OPPO WATCH3 series exposure may include the first Snapdragon W5, which will be launched in August

From the perspective of market performance, after @Oppo Zhimei Life released the f...