Some algorithms about random matrix
Author:Data School Thu Time:2022.07.24

Source: Paperweekly
This article is about 1500 words, it is recommended to read for 5 minutes
This article briefly introduces algorithms about Random Matrix.
This article introduces the algorithm about the random matrix GUE used in my master's dissertation. It is really super easy to make, who knows and knows! For a brief introduction to GUE, you can see:
https://zhuanlan.zhihu.com/p/161375201
The main reference of this article is [1] [2] [3]. All code is written in matlab.
Then let's review first, the definition of Gue:
DEFINITION 1.1 (GAUSSIAN Unity EnsembLE) assumes that
Then

https://zhuanlan.zhihu.com/p/161375201
The main reference of this article is [1] [2] [3].All code is written in matlab.
Then let's review first, the definition of Gue:
DEFINITION 1.1 (GAUSSIAN Unity EnsembLE) assumes that
Then
Then, what we care about is his biggest feature value. We represent
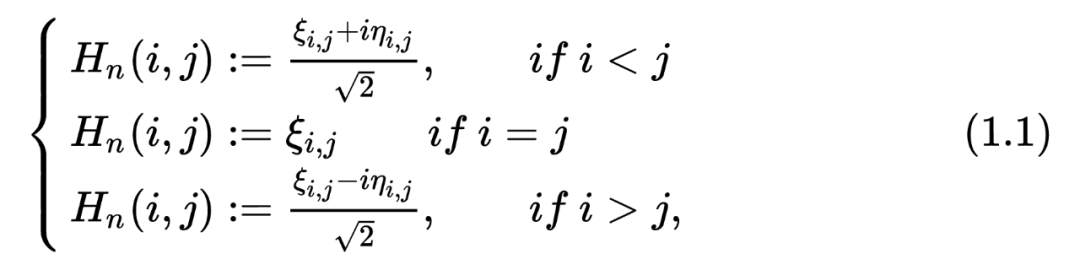
FUNCTION GUE = Gue_Matrix_mc_create_gue (SIZE, SEED) %Set Random Seed RNG (SEED); Tempmat = Randn+1II *randn (size); gue> (tempmat+tempmat ')/2; end

But this method is actually very difficult to use, there are two main reasons below:
The requirements for storage are very large, that is,
His requirements for storage are relatively low.
He is a bit special, and he can use some methods with low component algorithms to calculate his biggest feature value.
The distribution of his biggest feature value is that
In [1], the two authors proved that the following matrix met these three requirements:
This is
Then we can achieve his structure through the following code:

FUNCTION TRIMAT = GUE_MATRIX_MC_CREATE_TRIMAT (SEED) %set rate rng (seed); %set subdiation/site Distitived d = sqrt (1/2)*sqrt (chi2RND (beta*[size: -1: 1]) '; %set up digonal d1 = (randn (size, 1)); Trimat = spdiags (d, 1, size, size)+spdiags (D1,0, size, size)+spdiags (D, 1 , size, size) '; end
This method is really good. Through observation (2.1), we can find:
We only need
He has the structure of Tridigonal and Irreducible (because the element A.S. on his Sub-Digonal is not equal to 0), then we can use some powerful algorithms to calculate his biggest feature value! For example, Bisection Method (this method is really good, if you are interested, you can read this book [4] lecture 30). His algorithm complexity is only
In the following
Then the size of the matrix
I do n’t post the code about Bisection Method. After all, I also downloaded it from others. If you want to download, you can go to the author's homepage of [2] (http://www.mit.edu/).
However, the above three methods are essentially the repair of the MONTE Carlo method. It does not overcome the
here
in
It is the
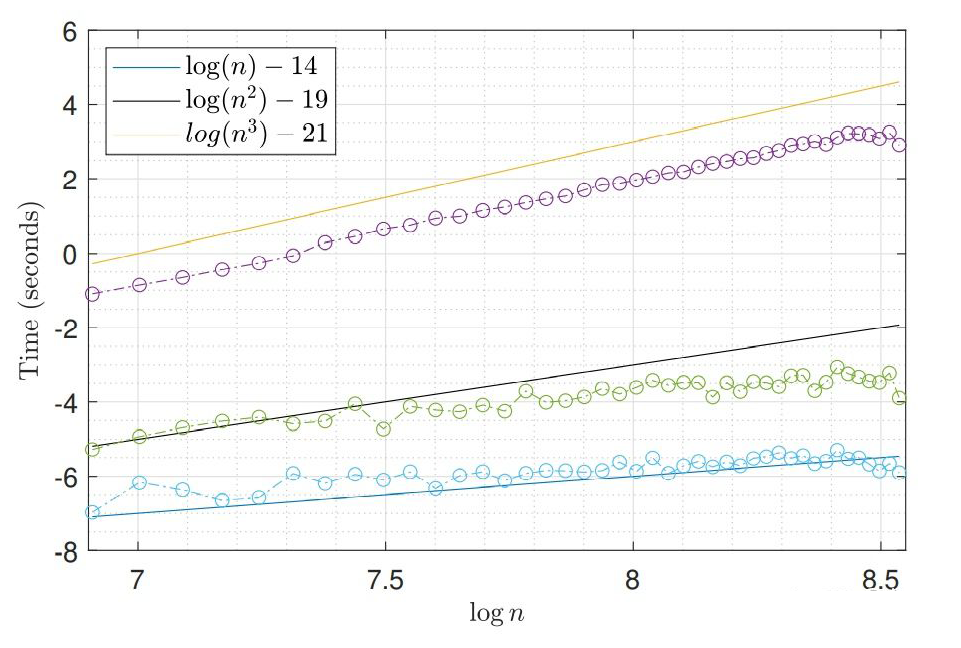
Then let's observe the
Theorem 2.1 Assuming
Then
That is defined in
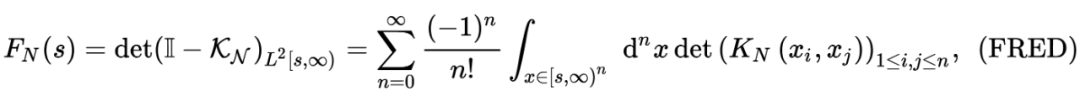
Function [Result] = STEP_TASEP_CDF (SIGMA, T, S) s = Step_tasep_proper_interval (t, sigma, s); c2 = sigma^(-1/6)*(1-sigma^(1/2))^(2/3); delta_t = c2^(-1)*t^(-1/3 (-1/3 );/code> code in Bornemann Method's code The place is used above. Inside we do not need to choose n = sigma*t; max = (t+n-2*(sigma)^(1/2)*t-1/2)/(C2) *t^(1/3)); for k = 1: length (s) if s (k) & max Result (k) = 1; Else s_resc = s (k)+delta_t; x = s_resc: delta_t: max; x = x '; Result (k) = DET (EYE (Length (X))-Step_tasep_kernel (T, Sigma, X, X, X, X )*delta_t);%Bornemann Method End END
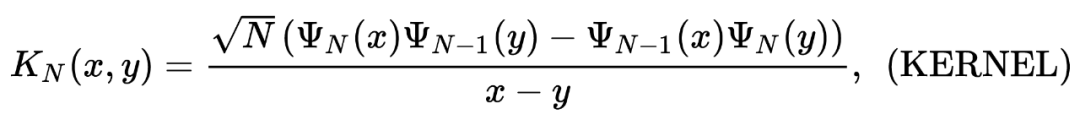
https://arxiv.org/pdf/0804.2543.pdf
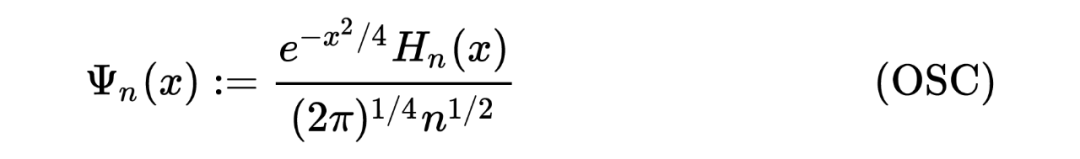
This article briefly introduces algorithms about Random Matrix. After that, it may introduce things related to KPZ-Universality, that is, my own direction, it is really interesting!
references:
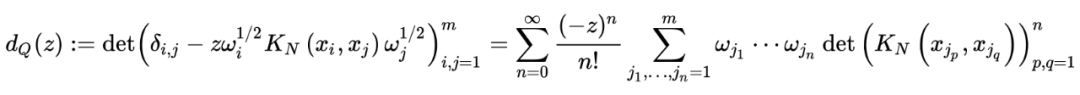
[1] Dumitriu I, Edelman A. Matrix Models for Beta Ensembles [J]. Journal of Mathematical Physics, 2002, 43 (11): 5830-5847.
[2] ERSSON P O. Random Matrices. Numerical Methods for Random MatriceS [J]. 2002.

[3] Bornemann F. On the Numerical Evaluation of Fredholm Determinants [J]. Mathematics of Computation, 2010, 79 (270): 871-915.
[4] Trefethen l n, Bau III d. Numerical Linear Algebra [m]. Siam, 1997.
Edit: Yu Tengkai
- END -
Ministry of Foreign Affairs: The BRICS "China Year" plan continues about 80 meetings and activities
Xinhua News Agency, Beijing, July 4th (Reporter Warm) Zhao Lijian, spokesman for the Ministry of Foreign Affairs, said on the 4th that the BRICS China Year was just over half. In the second half of
Can you win the prize?Xian'an Police successfully destroyed a telecommunications network fraud

Jimu Journalist Cheng YuxunCorrespondent Xu Chengcheng ShizhaoOn June 9th, the ant...