There is no 3D convolution 3D reconstruction method, only 70ms reconstruction on A100 only needs 70ms
Author:Data School Thu Time:2022.09.27

Source: Heart of the machine
This article is about 1500 words, it is recommended to read for 5 minutes
This article comes from researchers from Niantic and UCL and other institutions using carefully designed and trained 2D networks to achieve high -quality depth estimates and 3D reconstruction.
3D indoor scenes from attitude image reconstruction are usually divided into two stages: the depth estimation of the image, and then the depth combine and the surface reconstruction. Recently, a number of studies have proposed a series of methods to implement rebuilding directly in the final 3D volume feature space. Although these methods have obtained the impressive reconstruction results, they depend on the expensive 3D convolutional layer and limit their applications in limited resources.
Now, researchers from Niantic and UCL and other institutions have tried to re -use the traditional methods and focus on high -quality multi -view depth prediction. Finally, the simple and ready -made deep fusion method is used to achieve high -precision 3D reconstruction.

Thesis address: https: //niaclabs.github.io/simplerecon/resources/simplerecon.pdf
Github address:
https://github.com/nianticlabs/simplerecon
Thesis homepage:
https://nianticlabs.github.io/simplerecon/
not
The study was carefully designed with a powerful image aire and the amount of characteristics and geometric losses, and a 2D CNN was carefully designed. Simplerecon has achieved significant leading results in depth estimates, and allows online low memory reconstruction.
As shown in the figure below, Simplerecon's reconstruction speed is very fast, with only about 70ms per frame.

not
The comparison results of Simplerecon and other methods are as follows:

not

not
method
The depth estimation model is located at the intersection of the monocular depth estimation with the plane scanning MVS. Researchers use Cost Volume (cost volume) to increase the depth predicted encoder -decoder architecture, as shown in Figure 2. The image encoder extracts the matching feature from the reference image and source image to enter the Cost Volume. Use the 2D convolutional encoder -decoder network to process the output of the Cost Volume. In addition, the researchers also use the image -grade features extracted by a separate pre -trained image encoder for enhancement.
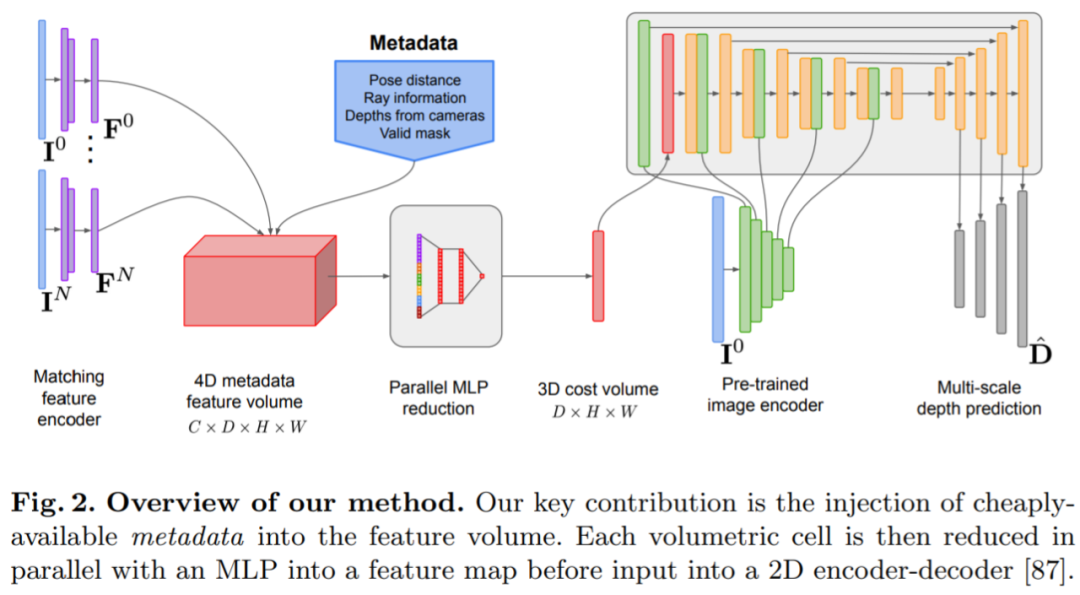
The key to the study is to inject existing metadata and typical deep image features into the Cost Volume to allow online access to useful information, such as geometry and relative camera posture information. Figure 3 detailed the Feature Volume structure. By integrating these previously unopened information, the model of this study can be significantly better than the previous method in depth prediction, without the need for expensive 4D Cost Volume costs, complex time fusion, and Gaussian process.

This study is implemented using PyTorch and EfficientNetV2 S is used as the main trunk. It has a decoder similar to UNET ++. In addition, they also use the top 2 blocks of ResNet18 for matching feature extraction. The optimizer is ADAMW. It took 36 hours to complete.
Network architecture design
The network is implemented based on the 2D convolutional encoder -decoder architecture. When building this network, research found that there are some important design options that can significantly improve the accuracy of depth prediction, mainly including:
Cost Volume fusion: Although the RNN -based time fusion method is often used, they significantly increase the complexity of the system. Instead, the study makes the Cost Volume integration as simple as possible, and it is found that the point matching costs between the reference view and the point of each source view can be simply added to the result of the competition with SOTA in depth.
Image encoder and feature matching encoder: Previous research shows that the image encoder is very important for depth estimates, whether in monocular and multi -view estimates. For example, DeepVideomvs uses mnasnet as an image encoder, which has a relatively low delay. The study recommends that the small but more powerful EfficientNetV2 S encoder is used. Although the cost of doing so is increased the parameters and reduced the execution speed by 10%, it greatly improves the accuracy of in -depth estimates. Fusion Multifabic image features to Cost Volume encoder: In deep three -dimensional and multi -view three -dimensional based on 2D CNN, image features are usually combined with the Cost Volume output on a single scale. Recently, DeepVideomvs proposes to splicing depth image features on multiple standards, adding jump connections between the image encoder and the Cost Volume encoder to all resolution. This is very helpful for LSTM -based fusion networks, and the study found that this is equally important for their structure.
experiment
The study trained and evaluated the method mentioned on the 3D scenario reconstruction dataset scannetv2. Below 1 uses indicators proposed by EIGEN et al. (2014) to evaluate the depth prediction performance of several network models.
not

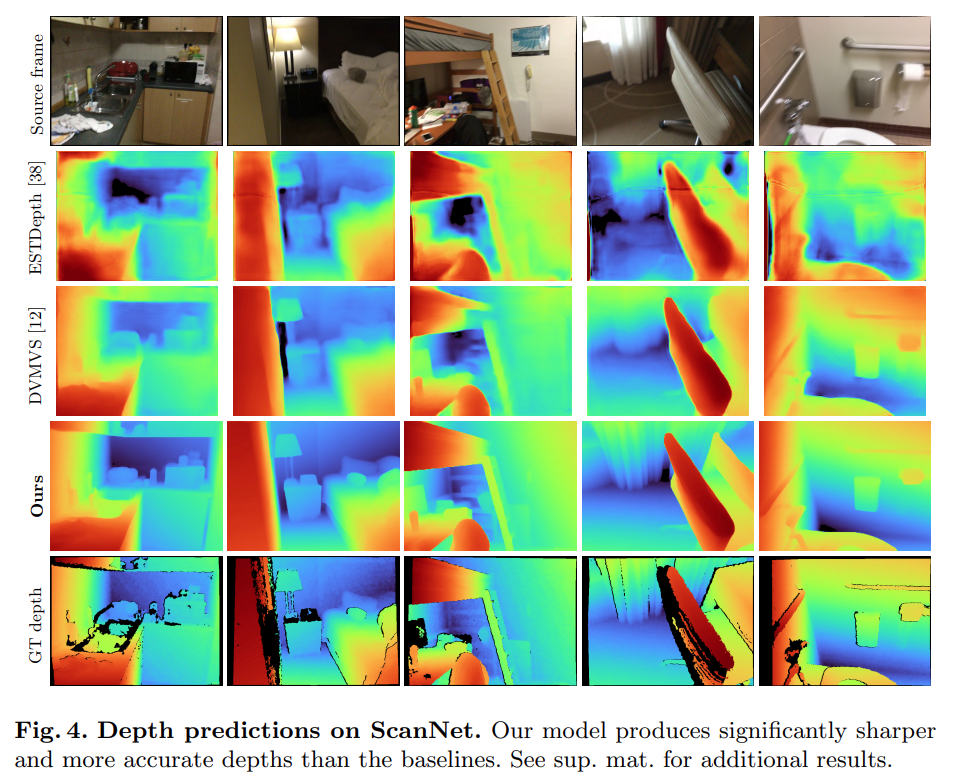
Surprisingly, the underlying model of the institute does not use 3D convolution, but it is better than all baseline models in depth prediction indicators. In addition, the baseline model that does not use metadata -encoded is better than previous methods, which indicates that the 2D network of carefully designed and trained 2D networks is enough to perform high -quality in -depth estimates. Figures 4 and Figure 5 show the qualitative results of depth and legal lines.
not
not

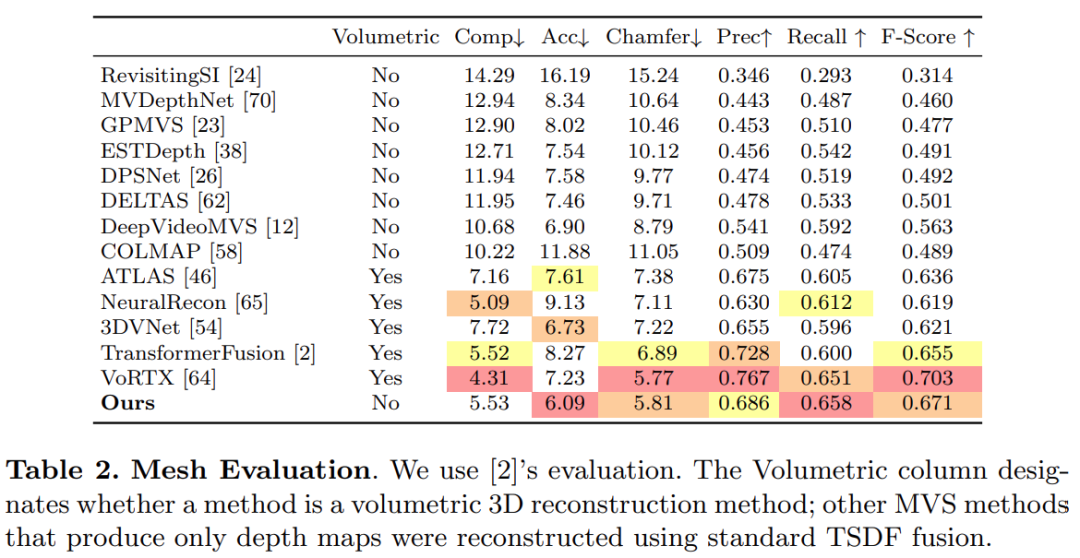
The study uses a standard protocol established by the TransformerFusion for 3D reconstruction evaluation. The results are shown in Table 2 below.
It is critical to reduce sensor delay for online and interactive 3D reconstruction applications. Below 3 shows a given new RGB frame, the integration time of each model on each frame.
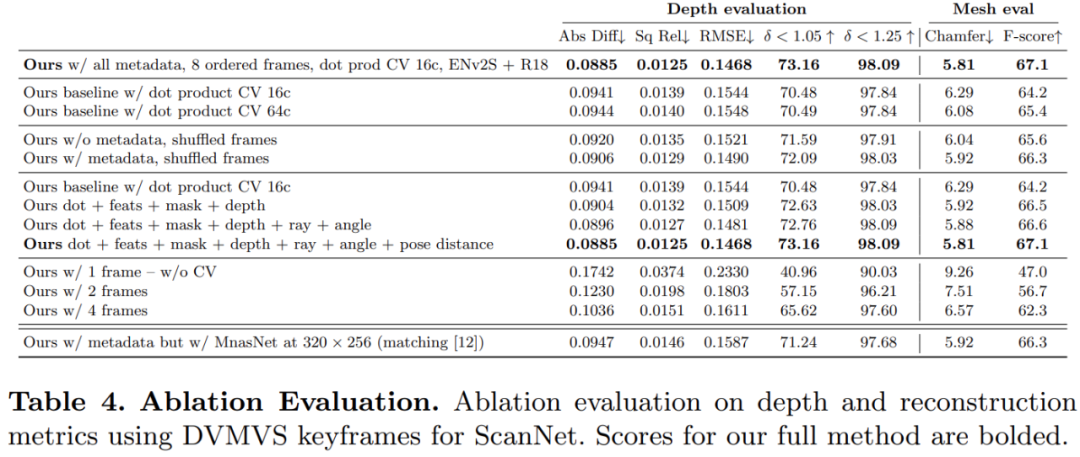
In order to verify the effectiveness of each component in the research method, the researchers conducted ablation experiments. The result is shown in Table 4 below.

Edit: Wang Jing
- END -
Recommend a few high -quality public accounts with depth and dry goods
Several public accounts recommended to you today not only produce high -quality timeliness content, but also provide a variety of diversified content angles worthy of your ownAt the same time, pay att
Summer 丨 Qingfeng Xu Lai

From the summer clouds, the cool wind rises. Chi Qiu came again, and the lotus flo...