ACL2022 | Kpt: Prompt Verbalizer, which integrates knowledge in text classification
Author:Data School Thu Time:2022.06.25

Source: tsinghuanlp, deep learning natural language processing
This article is about 2400 words, it is recommended to read 5 minutes
This article uses the knowledge base to expand and improve the label words, and achieve better text classification effects.

background
The use of Prompt Learning (prompting learning) to perform text classification tasks is an emerging method of using pre -training language models. In the prompt learning, we need a tags to mappore (Verbalizer) to label the predictive transformation component class of the vocabulary in the [MASK] position. For example, under the mapping of Politics: "Politics", Sports: "Sports", the pre -training model will be regarded as the prediction score of the label word of Politics/Sports as the prediction score of the label Politics/Sports.
The Verbalizer obtained by manual definition or automatic search has the shortcomings such as small and strong coverage. We use the knowledge base to expand and improve the label words, and achieve a better text classification effect. At the same time, it also provides a reference for how to introduce external knowledge under the Prompt Learning.
method
We propose to expand the labels of the knowledge base. Through tools such as related words, emotional dictionaries, etc., the initial labels defined by manual definition are expanded. For example, you can expand Politics: "Politics", Sports: "Sports" into the following words:
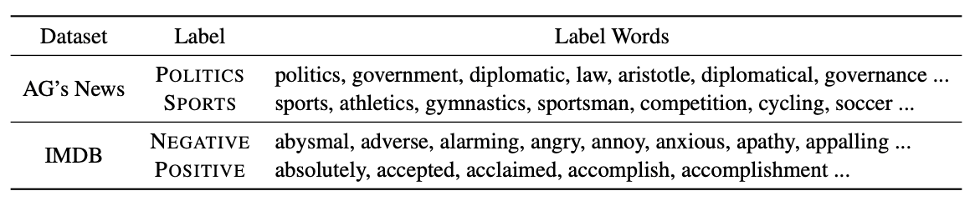
Table 1: Labels based on the expansion of the knowledge base.
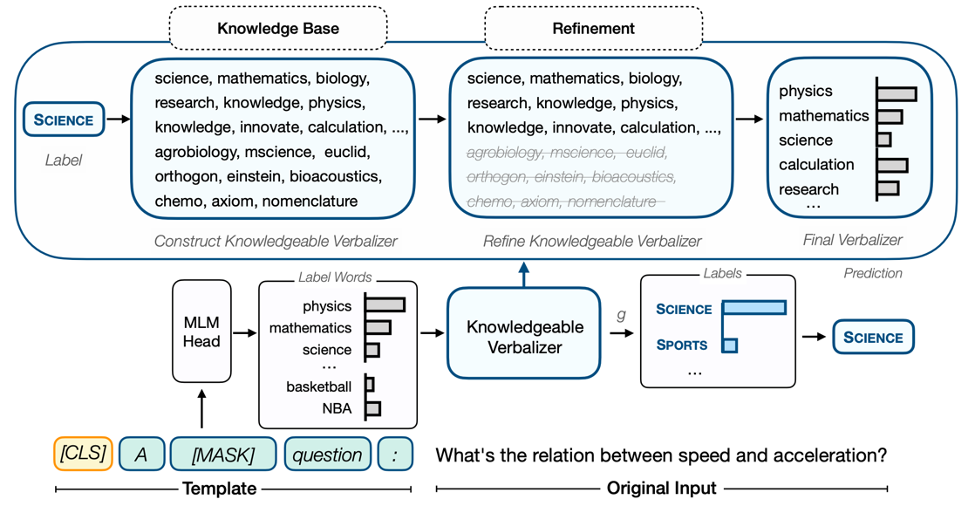
Figure 1: Kpt flowchart based on the classification task as an example.
After that, we can map the prediction probability on multiple words to a tag through one -to -one mapping.
However, because the knowledge base is not tailored for pre -training models, the labels expanded by the knowledge base have great noise. For example, the Movement expanded by Sports may be related to the Politics, which causes confusion; or the Machiavellian extended by Politics (which is not available to seize power) may not be predicted, or even disassembled into it. Multiple token does not mean the words itself.
Therefore, we proposed three types of precision and a calibration method.
01. Frequency refinement
We use the pre -training model M itself to the output probability of label V as the prior probability of the label word, which is used to estimate the frequency of the priority of the label. We remove the labels with a small frequency.
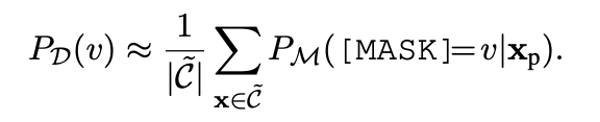
Formula 1: Frequency refinement. C represents the corpus.
02. Relative refinement
Some labels and labels are not correlated, and some labels will be confused with different labels at the same time. We use TF-IDF's thoughts to give each label an importance to a specific category.
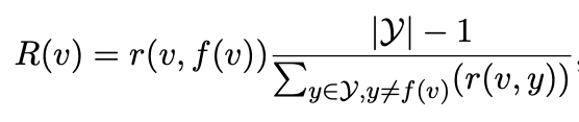
Formula 2: Relative refinement, R (V, Y) is a tag V and tag y correlation, similar to TF item. One item on the right is similar to the IDF item. We ask this item to require V and its non -corresponding classes.
03, can learn refined
In a small sample experiment, we can give a learning weight to each label, so the importance of each label word becomes:
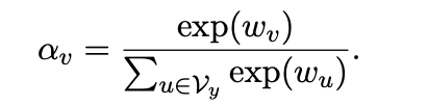
Formula 3: Learned label weight.
04. Calibration based on context
The priority probability of different label words in zero -sample experiments may be much worse. For example, predicting Basketball may naturally be larger than Fencing, which will affect many niche tag words. We use calibration to balance this effect.

Formula 4: Based on the calibration of context, the denominator is the prior probability of formula 1.
Using these refined methods above, the labels expanded by our knowledge base can be effectively used.
experiment
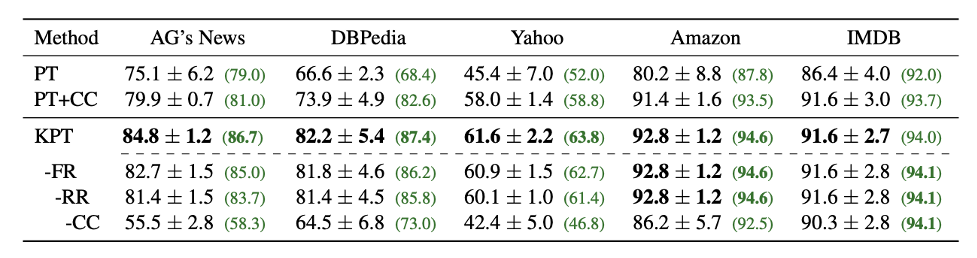
Table 2: Sample text classification tasks.
As shown in Table 2, compared to ordinary Prompt templates on zero samples, the performance has a significant growth of 15 points. Compared with the addition of tags, it can also increase at most 8 points. The frequency precision and correlation are also useful.

Table 3: Little sample text classification tasks.
As shown in Table 3, the relevant essence of the learning essence and combination of the learning essence of the less samples has also greatly improved. Auto and Soft are automatic label optimization methods. Among them, Soft is initialized with artificially defined label words. You can see that the effects of these two methods are not as good as KPT.

Figure 2: The labels of the knowledge base extension of the Sports and Business classes contribute to predicts.
The visualization of labels shows that each sentence may rely on different label words to predict, and the expectations of our coverage are completed.
Summarize
Prompt Learning, which has attracted much attention recently, In addition to the design of Template, the design of Verbalizer is also an important link to make up for MLM and downstream classification tasks. The expansion of the knowledge base we proposed is intuitive and effective. At the same time, it also provides some references for how to introduce external knowledge in the use of pre -training models.
Related Links
Thesis link:
https://arxiv.org/abs/2108.02035 code address:
https://github.com/thunlp/knowledGeprompttuning
Edit: Yu Tengkai
- END -
"From zero to one" innovation continuously
[Struggler is youth]The vast starry sky, invisible exploration.In the past few days, the news of the successful flying flying of Shenzhou 14 has made all Chinese children jumping. But there are a grou
Takeaway is no longer a loss of money, but Meituan is still confused

It has been almost ten years since entering Meituan (03690.HK) to enter the takeaw...