A hot search two faces, the "high imitation hot search" in the entertainment industry lie to you?
Author:Shell net Time:2022.07.26
On the surface, there are more than just "yin and yang contracts" on the ground. Recently, new "Yin and Yang Topics" has appeared in the entertainment industry.
A few days ago,#几 决 Qianxi decided to give up the topic of entry#几 几 几 几 几 几 几, but then some netizens found that it was the same word. Essence

Are you stunned by this passage?
Don't doubt that this is not the difference between "Li Yan" and "Li Gui". These two topics under the default font of Weibo are exactly the same, and they cannot be identified with the naked eye. However, after replacing the default font under the Android system, you can see that the word "enter" of hot search topics is wrong. Some netizens said that the two "entered" were copied in the Xinhua Dictionary APP. The "entry" of hot search topics could not be found.


Why does this happen?
After reading the character code with Python, you can see that the "enter" in the hot search is not the "enter" (U+5165) in the common Chinese characters in Chinese, so it is not included by the font library. There is no inclusion of this character. No matter how the font changes, it will always stay on Microsoft's black font. It is not a Japanese text that everyone has speculated before, and its true body is the "enter" (U+2F0A) in the Kangxi dictionary.

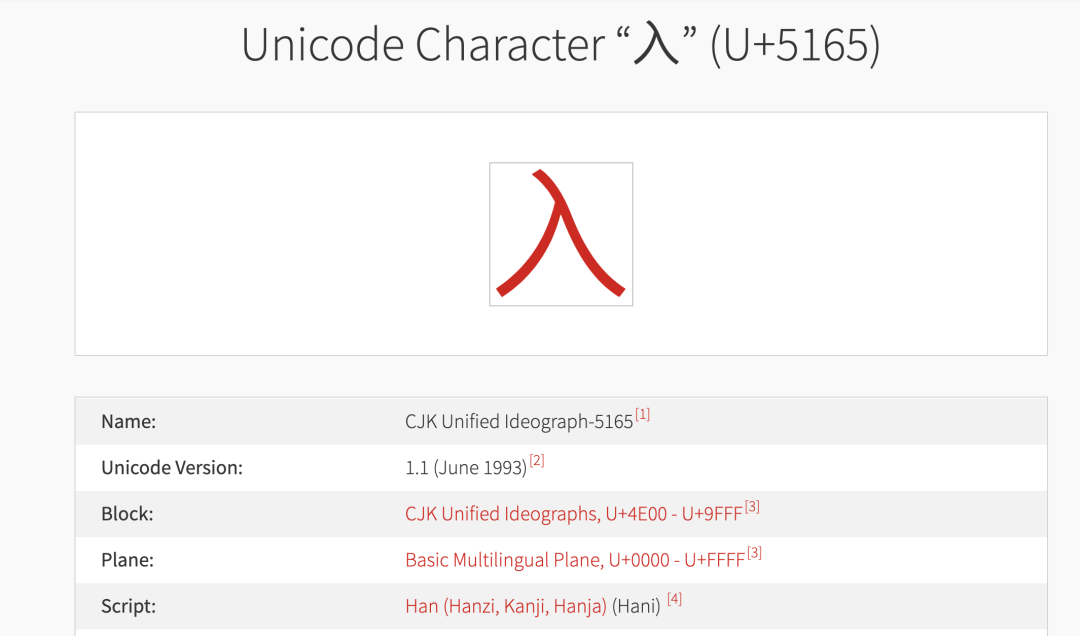
The picture above shows the Kangxi dictionary "enter", the picture below is the Chinese character "enter" | unicode official
The topic of yin and yang concealed the words "enter" in the history of the sky in the sky and a system ... These things are actually not new in the history of the Internet. Use similar characters to deceive users to hook themselves.
Extremely high imitation account
Not only "的 (U+2F0A)" and "U+5165". Open the official website of the Unicode. In the first part of the Kangxi Ministry, there is a full page with the characters that are easily confused with Chinese characters.
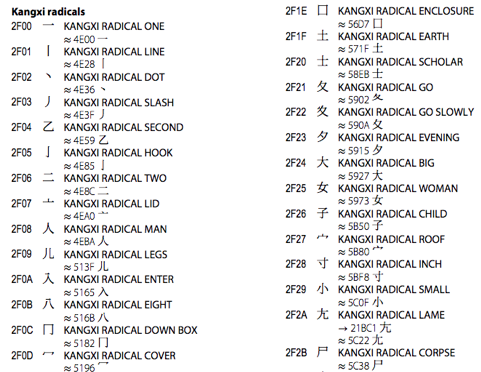
In addition, there are many shapes that exist in different encoding areas. For example, some polyphonic characters in South Korea are separated from the original concentration when coding. Unicode even launched a Sino -Japanese and Korean and capable text to include these special cases.
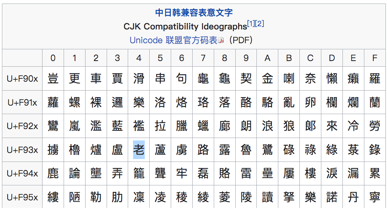
It looks the same word as Chinese, in fact, the encoding is completely different | Wikipedia
This encoding method takes into account the habits of various language users, but the problems brought are also obvious: in the eyes of the computer, as long as the encoding is different, the system will be considered to be two completely different words, and in the eyes of human users The appearance of these characters is exactly the same.
Of course, the scammers will not be placed in vain. A network attack method called Idn HomoGraph Attack was born. Early scammers to confuse users by using 0 instead of O and 1 instead of L, while the upgraded version of the unicode same -type character in switching directly makes people "blind".
For example, there are actually two "teachers, my classmate" on station B. Among them, the name of the fake He He, the "old (U+F934)" of "Good Teacher" uses it. coding.

Left: Old (U+8001) Division, my classmate, right, right: Lao (U+F934) Division, my classmate He. Classmate He on the "true and false" on station B. This is a pixel -level high imitation. How can people recognize it! | Bilibili
Not only did Chinese characters encounter such problems, the high imitation scammers in the alphabet world are even more outrageous.
In 2017, a high imitation app appeared in Google's official app store. It directly disguised as a well -known chat software WhatsApp (equivalent to US WeChat). The developer adds a visible Unicode character behind the software name to make it look different from formal software. This operation directly deceived more than 1 million users and made it one of the most "successful" malware.
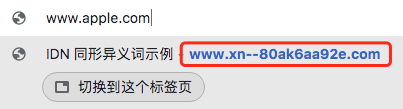
The URL could not escape "someone imitates my face." As the international domain name is open to use Unicode, the "English" you see may not be English! For example, if you copy it in the browser, the browser will tell you if you copy it to the browser ...

This website that looks exactly the same as Apple's website is applied by computer enthusiast Xudong Zheng. The а (U+0430) in the URL is not an English letter, but a Silil letter. As long as you click in, you will enter the "fishing website" of Xudong Zheng. Similar similar -shaped alien attacks are often used in spam and virus files.
"Culprit" Unicode
However, such a "unscientific" Unicode is already the most common and best character solution at this stage.
To let computers understand human language, it is necessary to establish a bridge between humans and computers, that is, a encoding method that needs to convert characters into numbers.
In the 1960s, when the computer was born, Americans used a code to express English and various symbols. This encoding has only one byte, which can represent 256 (2^8) characters (8 binary numbers). Although only 128 characters are defined, it is enough to cover the English letters and some common symbols of writing. coding.
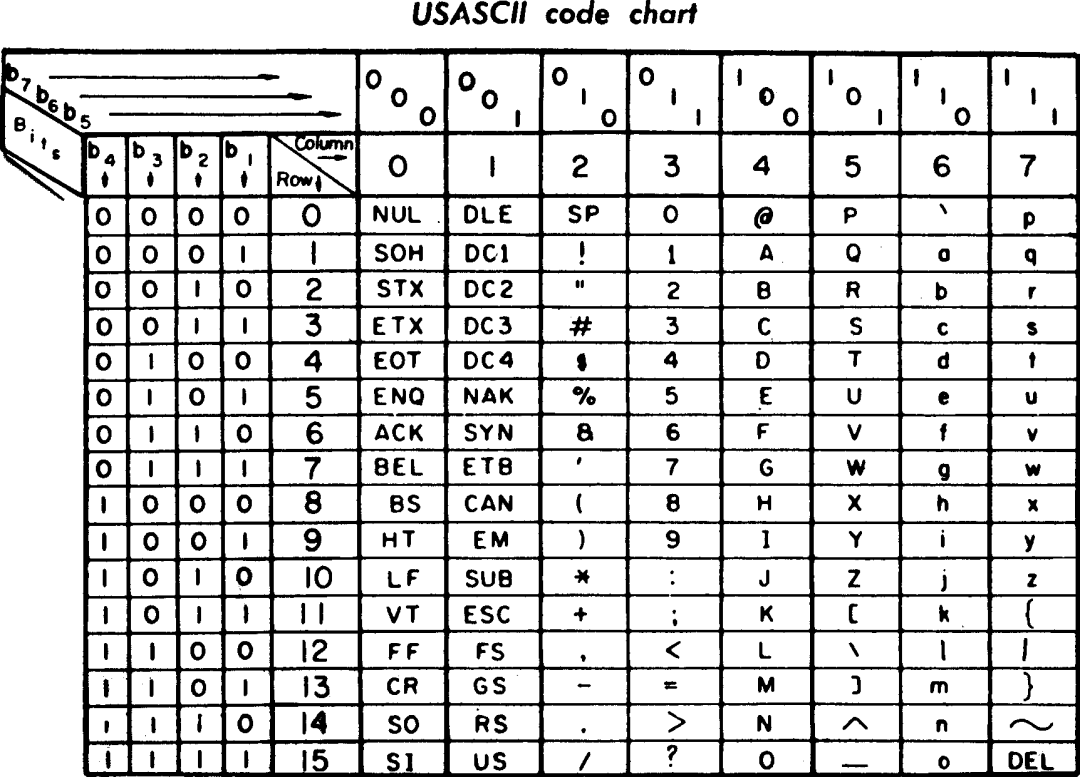
The ASCII encoding table used before 1972. At that time, the computer only recognized these characters | Wikipedia. However, with the development of computer technology, simple English characters were gradually not enough. The needs of various languages such as Chinese, French, Japanese, etc., and each new language needs new characters. So every country also set out to create its own encoding solutions, such as my country's GB 2312, GBK.
Different countries and regions each use the results of different codes, that is, computers must install different decoding software every time. Once the decoding error occurs, users can only see a bunch of garbled code.
Some of the bigger garbleds, the online surfing can always be seen for a long time

At this time, some international organizations began to formulate a unified character encoding scheme to set the unique binary encoding for each character in each language to meet the requirements of cross -language and cross -platform text conversion and processing. Essence In this language environment, there is no need to decode the files separately, and the content of any language can be displayed on the same screen.
UNICODE uses numbers 0-0x10ffff to map these characters, which can accommodate up to 1114,112 characters, or 1114,112 codes. The code is the number that can be assigned to the character. UTF-8, UTF-16, UTF-32 are encoding schemes that convert numbers to program data. Convert characters to numbers and character coding can be briefly understood, and each character is allocated to a number, such as: a = 65, a = 97. If this code is uniform, all computers in the world can recognize these characters.

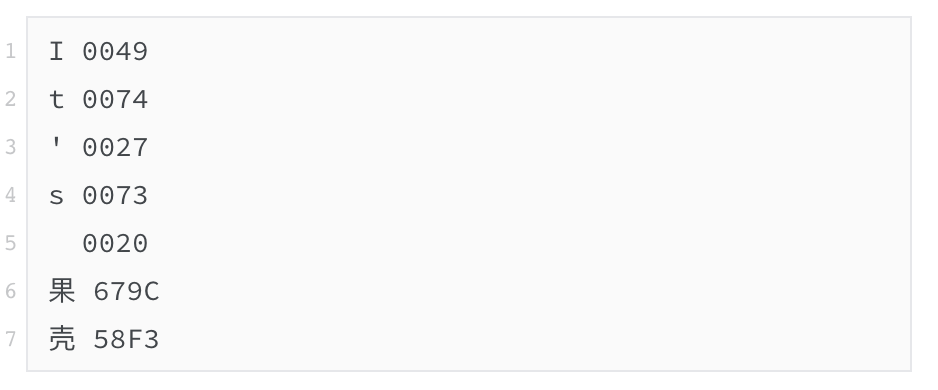
We have allocated a unique encoding to each character, so how to make a computer know this encoding? Since the computer only understands the binary like 0 and 1, the easiest way is to directly convert the encoding into two -proof, for example: the Unicode encoding of the IT ’s fruit shell is as follows:
The corresponding binary is:
At the beginning of the release of Unicode in 1991, only 7,161 characters were supported. Although it was much more than 128 ASCII codes, it was still not enough to meet the needs of global users. In the next few decades, Unicode continued to iterate, with more support language, and the number also surged to 140,000. Among them, there are not only characters such as Myanmar and Tibetan. , Introduction to the Book of Princess, Domino's cards, non -language symbols.

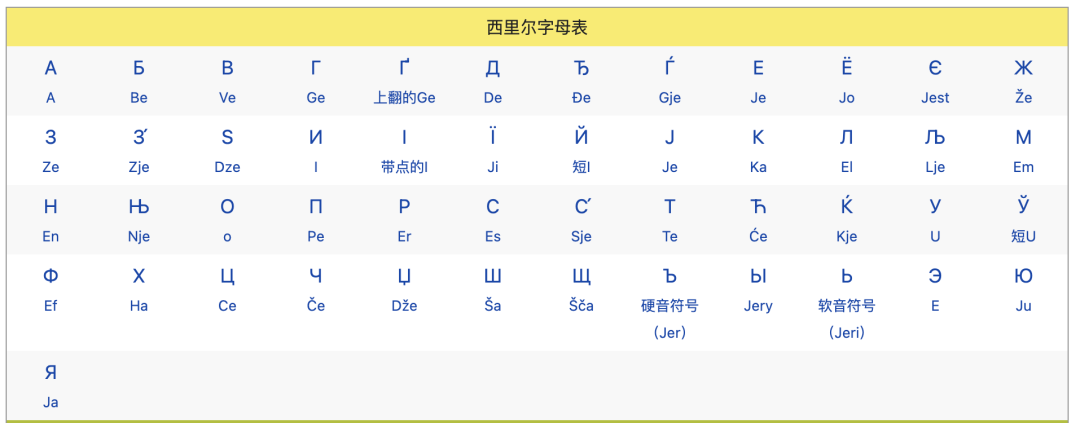
When adding unicode, you need to adhere to the principle of "unification", that is, unify the same characters in the same writing system (Scripts) of different languages, so the code of the same Chinese characters in China, Japan and South Korea is consistent Essence But at the same time, the rich language also contains a large number of near -shape characters. For example, some characters in the Cyril letter are similar to the height of the English letters. There is really no good way to identify it. You can only view the code.
Cyrine Alphabet | Wikipedia
Borrow me with me a pair of wisdom eyes
Although the wisdom that Na Ying borrowed could not help any busy, we can still use some other ways to see the truth.
For the "counterfeit" website using unicode muddy water, each browser has begun to convert the URL to a unified Ponycode code for display. And for such high imitation websites, the browser itself has corresponding comparison and review methods, and timely reminds users of the risks that may exist.
The browser will convert the unicode character into a unified encoding, to a certain extent resisting the fishing website
For high imitation accounts and text displayed on the page, you can quickly find cat greasy by changing the font. Unicode itself does not represent any font. The display effect of the final text has a lot to do with the presence of the system. Therefore, some fonts only display some characters in Unicode, and those words that are not adapted will look very different.
When the font is changed to the regular body, the second old word is obviously different

However, the change of font is not a hundred trials. At present, many websites will specify the displayed fonts in the code in order to unify the style, which is not affected by the user's change of its system font. Therefore, in the case of suspicious situations, the most fundamental method is to copy the text and query the unicode code.
Using Python3 can simply find the unicode encoding of a character, as shown in the following code:
This code can be performed through four steps:

Environment preparation. Open the Terminal that comes with the computer, enter Python3+Enter, and enter the Python interactive environment, and you can start writing code.
Variable assignment. Give the character you want to query to the variable S. For example, if we want to query the unicode encoding of the character "Old", enter s = 'Old'.
Unicode encoding query. Python's built -in Encode function can be used to query the Unicode code, enter the "unicode_escape" in the parameter of the enCode function, which means that the encoding type we want to query is unicode. Enter RE = s.encode ("unicode_escape") to retrieve the encoding.
Finally enter the print (re) to see the unicode code of the character. Compared with whether the encoding of any two characters is consistent.I hope that everyone will not be confused in the face of the so -called "yin and yang hot search", and use technical tools to protect themselves in front of the Unicode scam!
references
[1] https://en.wikipedia.org/wiki/idn_homography_attackhttps://ieeexplore.eeeeeeeeeecument/8376
[2] https://medium.com/@wanxiao1994/Unicode%E7%AD%89%E4%BBB7%E6%80%A7%E4%B8%8E6%Ad%A3%E8%A7%A7%A7%A7%A7%A7%A7%A7%A7%A7%A7%A7%A7%A7%A7%A7%A7%E8%E8%E8%E8%E8%E8%E8%E8%E8%E8%E8%E8%E8%E8%E8%E8%E8%E8%E8%E8%A7%A7%A7%A7%A7%E8%E8%E8%E8%E8%E8%E8%E8%E8que84%E5%8C%96-2EB50B343BC1
[3] https://www.unicode.org/reports/tr36/
[4] https://www.sohu.com/a/202557787_114760
[5] https://support.mailessentials.gfi.com/hc/en-s/articleS/360015112900-rove-spam-Inicode-character-Adl.acm /doi/10.1145.145145.145145.145145.145145.145145.145145.1451414141414141490149914991414141091410.11 that1 that
[6] https://www.xudongz.com/blog/2017/idn-Phishing/
Author: tree, OWL
Edit: Turn over
- END -
Line tension, painter from British artist Peter Peri

Peter Peri, British artist, born in 1971. The works of British artist Peter Per...
Chuan Tuotuo's inheritor Ma Jian: Chenggu Tuo's new inheritance cultural mission
This is a purple sand pot all -shape extension. On one side of the pot, there is a clear line of fish, and the other side is \more than the year\. This full shape is made by the built by the pionee